The Ultimate Git Flow: Trunk-Based Development and Stacked PRs for the Win

👋 Hey! I'm Jakub Beneš, a Software Engineer based in Prague.
I'm passionate about scaling engineering, organizational design, and leadership. I'm a huge fan of web technologies and modern approaches within this field. While I'm a strong contributor on the frontend side, lately, I've been focusing more on the entire stack and infrastructure because there's often low-hanging fruit that can deliver a massive impact – and I enjoy seizing such opportunities. I'm not sure if I'll ever start liking YAML, though. 🤓
Hmm, the title sounds a bit clickbaity, doesn't it? However, I would like to take the time to discuss the git flow I'm using, what it entails, and why I believe it is essential for high-performing teams in this article.
As always, I write this article mostly for myself. Not that I would believe that I would suddenly lose my memory and start wondering what I'm doing here. Rather, I continue in my efforts to document what I believe works well, so I have an easier time passing this information around in this format. In the past, I would probably have used Twitter for this, but recently I decided that every time I have a big urge to share something bigger, I would write an article about it. So here we are.
I believe there is no point in doing a fancy introduction of Git to you. You most likely know it very well. Git is one of the most popular distributed version control systems, which aims at tracking changes in your source code and thus making collaboration possible at scale. It would be an understatement to say that Git is popular; it is practically everywhere in modern software development. Let me know if you use something different and the reasons for that in the comments (pro tip: in that case, it might be a good idea to start looking for a new challenge; your career might need it).
Trunk-based development
There are lots of opinions on what is the best way of working with Git at small-to-big software product companies. I have a personal answer for that (and it is not that controversial), it is called trunk-based development. You might be using it, you just don't know it is named like this.
This idea is simple: in order to move fast, you need to ship fast, iterate, and do it all over again. (Shameless plug: you might enjoy my recent article about high-performing product teams and their mindset.) To reiterate what I just said, developers are encouraged to merge small, frequent updates to a "trunk" branch (usually conventionally called the "main" branch). Once the code is merged, it's all in the hands of CI/CD (I have some opinions on this topic as well); tests are run, code is built, and the app is shipped to customers. Everyone loves it. Rinse and repeat.

It might look like this: I create a branch with my feature, iterate on it (more about it later) and once it's ready, we do a review with the team. If everything is all right, we squash-merge it to the trunk branch.
There are many nuances to this one though. Firstly, you can technically do a fast-forward merge, where the commit ID would stay the same.
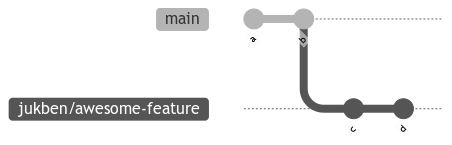
This is how it would look.

That is good in case you want to optimize for CI/CD runs. It is a good practice to make sure your PR is up to date with the main branch so you can be sure that the integration of your code is flawless. Otherwise, something that looks fine on your branch might be broken once it is put on top of the actual "trunk" branch.
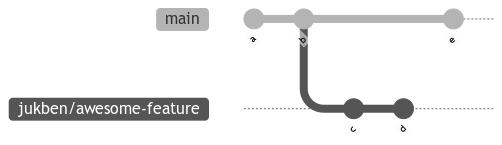
Consider something like this. Here, you can see that my feature is missing code from the commit with ID e which might (or might not) be important.
Anyway, back to my case (see the first image) – I tend to prefer squash merging. Making sure your commits are atomic (a fancy word for a commit that is self-contained) in a way that is worth keeping them in the history can be tedious, and trust me, if you have a big enough team, it might be hard to maintain consistency. To play it safe, I found that squashing the feature into one commit with a descriptive message is much better than adding 10 commits, most of which are "fix" or "wip".
There is one important point I have omitted so far. In order to do this, you have to separate deployment (which, as we said, should happen every time you merge something) from release. What does this mean? Simply put, you should be free to merge imperfect pull requests as soon as they do not break the whole system, putting everything down. How to do that? Feature flags, labs flags, call it what you want. The idea is that you are in control of what is available to the customer. With a system like this, you can eventually achieve rolling out features based on geography, user cohort, and more. The same goes for a fast rollback in case something goes wrong; you can just turn it off again. Boom. This sets a great mindset where the way forward is through iteration. Not even talking about derisking deployments; deployments will be so frequent that it won't be a big deal at all.
Stacked pull requests
There is a second part to what I have shared so far. Hopefully, you got the point with the fast pace of development that trunk-based flow enables. However, there is still at least one important part that we can take a deeper look at: pull requests or merge requests, if you like.
I don't want to explain why pull requests are essential in software development and the culture I'm trying to build as a leader. Not because I'm not passionate about the topic, but because I don't want to bore you to death. However, this is my article. I recently had a discussion where I had to defend pull requests as a source of knowledge sharing and expanding domain knowledge. It's not the only reason we love pull requests. It's also a great tool to make sure we ship the best code we can as a team. What's obvious to one person might be confusing to another. Pull requests are a great place to catch cases like this and make sure the trade-off makes sense, that stuff is documented, and that it is tested. I guess I will write something about code-reviewing culture someday in the future. For now, I guess you get the point.
I wrote a few paragraphs above about atomic commits. To make pull request review easier for your team, I highly recommend switching to atomic pull requests. These pull requests should be small and self-contained, tackling one problem at a time. I also like to introduce either behavioral change or structural change, not both together. There is more to this than meets the eye; in theory, it is simple, but it may sound tedious to juggle all the pull requests and make sure they can be built on top of each other.
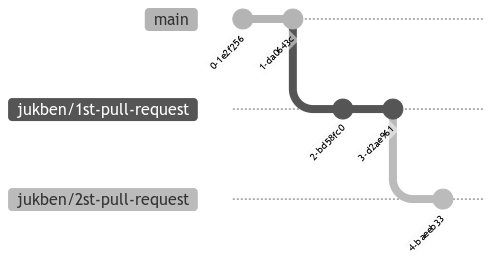
Imagine you have two pull requests open. The base branch for the second PR is the first one. This allows you to work with changes from the previous one, but streamline the conversation (and review itself) within the PR only to newly added code because the rest of it is covered in the first pull request (1st-pull-request). With this approach, you can keep building your complex feature and still make sure your pull request reaches the main branch swiftly. Not to mention the fact that smaller PRs are much easier to review. If you're really looking for a thorough review, what's the point in a review anyway? By stacking the pull requests on top of each other, you can resolve them concurrently; once the descendant is mergeable, you can do it, rebase the rest of them, and continue.
But imagine a situation in which someone made a good point about something in your first pull request, so you go and update it.
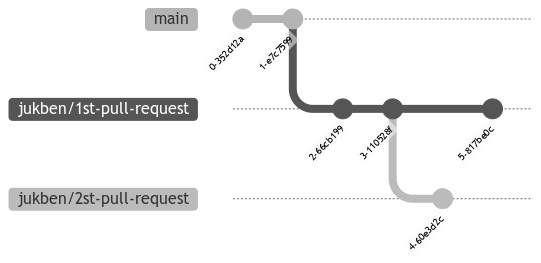
Now you have to rebase the second one in order to maintain the integrity of the stack. Isn't that too much work?
In a world without stacking, your second pull request would be blocked until you merge the first one, and that can be frustrating.
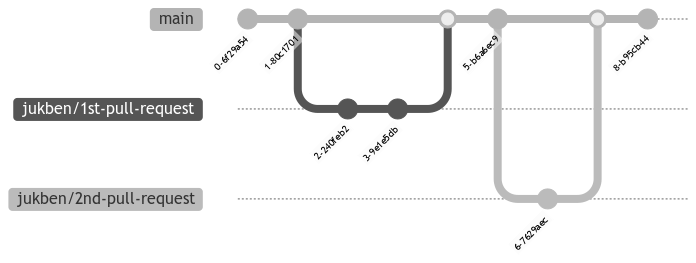
Yes, there has to be another way. You bet there is one.
Meet Graphite.dev
To my understanding, this flow is quite common in Big Tech; however, I have never worked for one of the mighty list. So, take it with a grain of salt. Though I don't have a reason not to believe it, it is really that productive.
Graphite is a product that enables just that (and more). It is currently in beta (I have some invites left, so if you are curious, feel free to reach out to me!). Their newly redesigned page does a great job of explaining how it works, so start there.
It's mostly two things: a dashboard which offers a slightly different take on Github's Pull Request (with a meme database so you can quickly comment with your favorite GIF). The UI helps you to eventually merge the whole stack with one click, but I rarely want that so I usually stay in Github anyway.
It is the CLI that matters the most. Do you remember the chore I described one must do in order to keep their stacked PR aligned with every commit they do? This heavy lifting is done by the CLI so you can stack and be cool about it.
It is worth saying that Graphite adds a bit of its own terminology to the game. There is "stack," "upstack," and "downstack." In case you use Git directly from the command line, you need to rewire your brain to gt (alias for graphite CLI), which is luckily proxied to Git. Any unrecognized command will be passed to Git. Though, if you are used to Git as I was, it might take some time to adapt.
Here is an example of the workflow to make it more visual.
gt log # this prints current stacks visually
gt add -A # add files, passthrough to git binary
gt branch create -m "my new feature" # create branch from currently staged files
# ... work on stuff
gt add -A
gt commit create -m "additional fix which might go in separate PR"
gt branch split # splits the stack by commits
# ... some time later
gt repo sync # pull latest trunk branch
gt branch checkout # pick stack you want to work on
gt upstack restack # ensure the current branch and each of its descendants is based on its parent, rebasing if necessary.
Don't worry if you are confused; I encourage you to try it. It's easier than it seems. Anyway, one feature I quite like is that whenever you run gt repo sync, it checks for merged/closed PRs and asks you to remove their local branch. With that, it's always easy to check out only relevant branches (stacks).
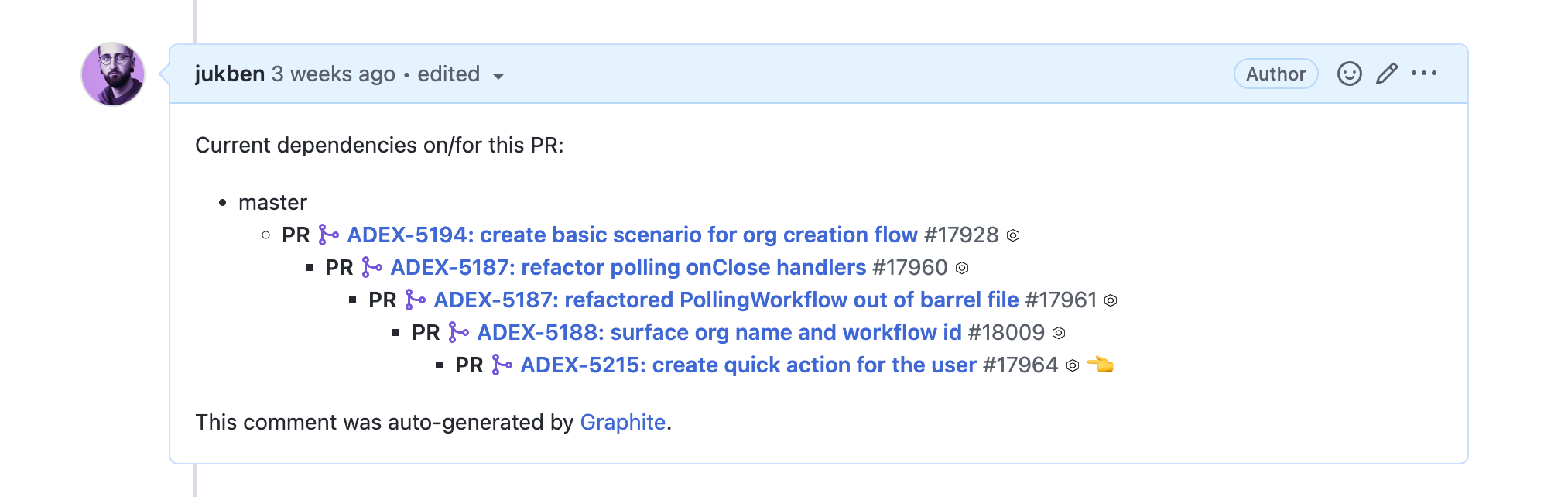
Every time you restack your stack, Graphite updates/rebases all the PRs affected by the change under the hood. Reviewers also understand that the PR is part of something bigger, as Graphite automatically references relevant pull requests.
Alternatives
Graphite isn't the only option on the market; there's also Sapling from Meta and ghstack. I haven't spent much time with them, but Sapling looks interesting. However, there are some caveats. The great thing about Graphite is that you can easily plug it into your company's workflow without causing any havoc. Pull requests are pretty much normal and easy to review when using Graphite. You can't say the same about Sapling, which has Git interoperability, but it's generally recommended to onboard reviewers as well, which is hard to imagine in my shoes. I'd be curious to learn if someone was bold enough to roll it out in a company with more than 100 engineers (except Meta of course! Haha, you thought you got me, right?).
One important note: all of those are focused on Github. It's not a big deal for me, because for the last 8 years all of the repositories I have contributed to have been there. But it might be a deal breaker for some. Though, the concept should be able to be generalized.
Future
Are you still with me? I hope you are! Graphite is still quite new and I'm curious about how it will shape up. I have to frankly say I'm not getting any extra value from the dashboard; I'd be happy with the CLI only. My secret dream, which I reveal to you as a reward for making it here, is that this CLI could be recreated with Github CLI (gh) using their extensions' capabilities. This would undoubtedly make a great service to the popularity of stacked PRs, as it would decouple the CLI and the Graphite Dashboard. In order to make sure Graphite CLI can update the pull requests based on your stack, you need to authenticate towards their API (thus you need an account there). However, I believe you should be able to do the same thing by calling the Github API directly from the CLI. Well, maybe in the near future, who knows? If you would like to take a stab and kick it off, let me know; I would love to help.



